A day at Applied AI Conf: agents, auth layers, and one big idea I keep thinking about
![]()
I don’t go to many conferences these days. Between the “AI is eating the world” keynotes and the vendor booths with free socks, the signal-to-noise ratio can get rough. But Applied AI Conf felt different on paper — smaller, more practitioner-focused, the kind of event where someone might actually show code. So I went.
I work as an SRE at deepset.ai, where I’m currently in the middle of replacing Datadog with an open-source observability stack and wiring it into an AI-native workflow. So my radar for anything about tooling, infrastructure, and how agents interact with the systems around them was tuned particularly high today.
Here’s what stuck.
Dust: agents are not a personal tool, they’re company infrastructure
The first talk was from Stanislas Polu at Dust — formerly at OpenAI, now co-founder — and the framing he opened with landed immediately: stop thinking of an AI agent as something that belongs to a person. Think of it as something that belongs to the organization.
His slide said “Agents Deserve Servers, Not Computers” — and the analogy is actually pretty clean. Today, most agent setups look like the personal computer model: one agent, one sandbox, one person. Dust is pushing toward a shared server model where a single agent (or set of agents) runs on shared infrastructure — SQLite db, custom UI, bash access, auth layer — accessible by humans, teams, and other agents alike.
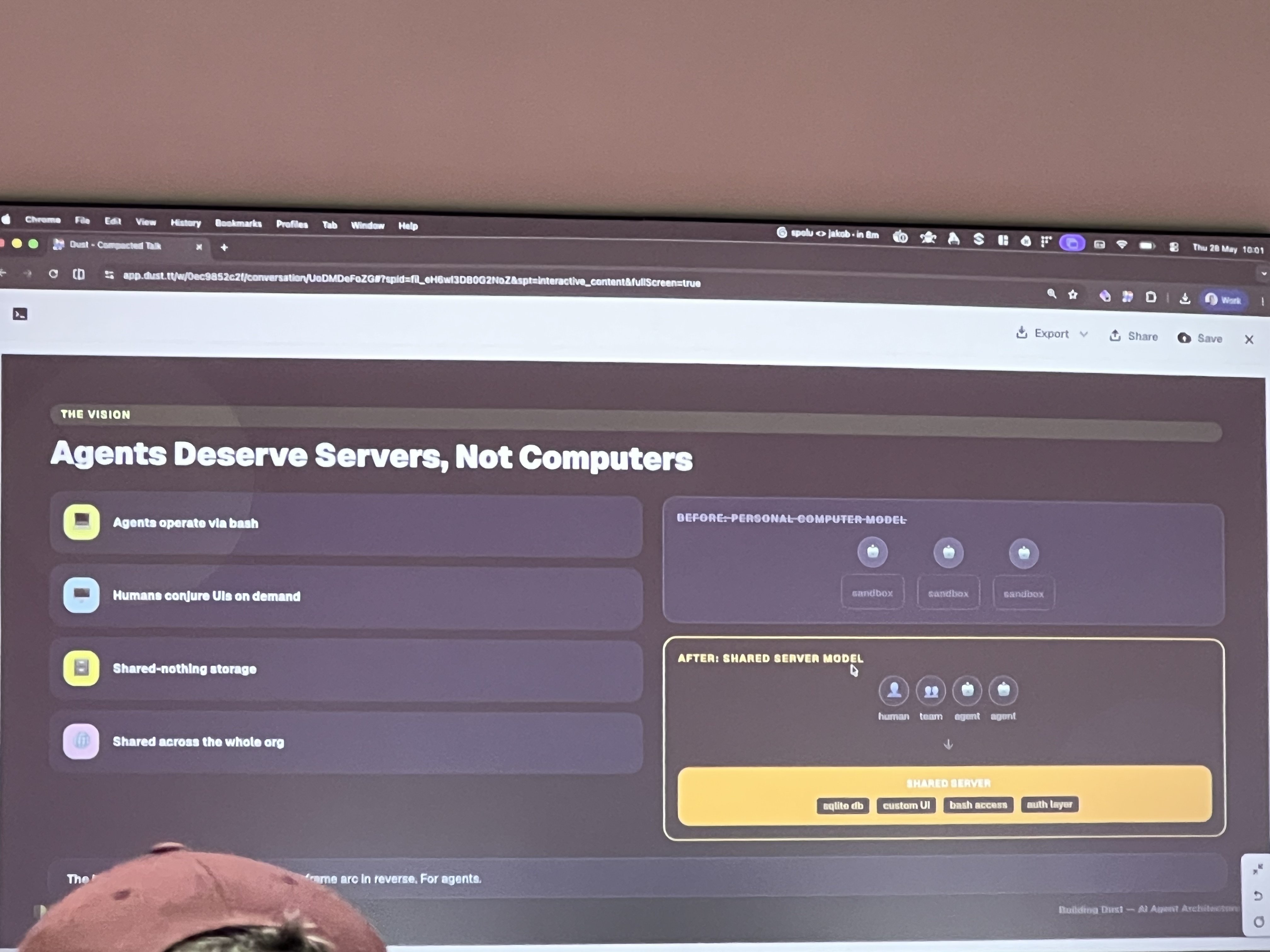
It’s one of those ideas that sounds obvious once you hear it but changes how you think about the problem. If you’re building tooling for a company — not just a personal productivity hack — agents probably shouldn’t be ephemeral processes that live and die per session.
The MCP vs CLI vs MCP CLI breakdown
The other thing from this talk I’ll be thinking about for a while: their comparison of integration patterns for giving agents access to tools.
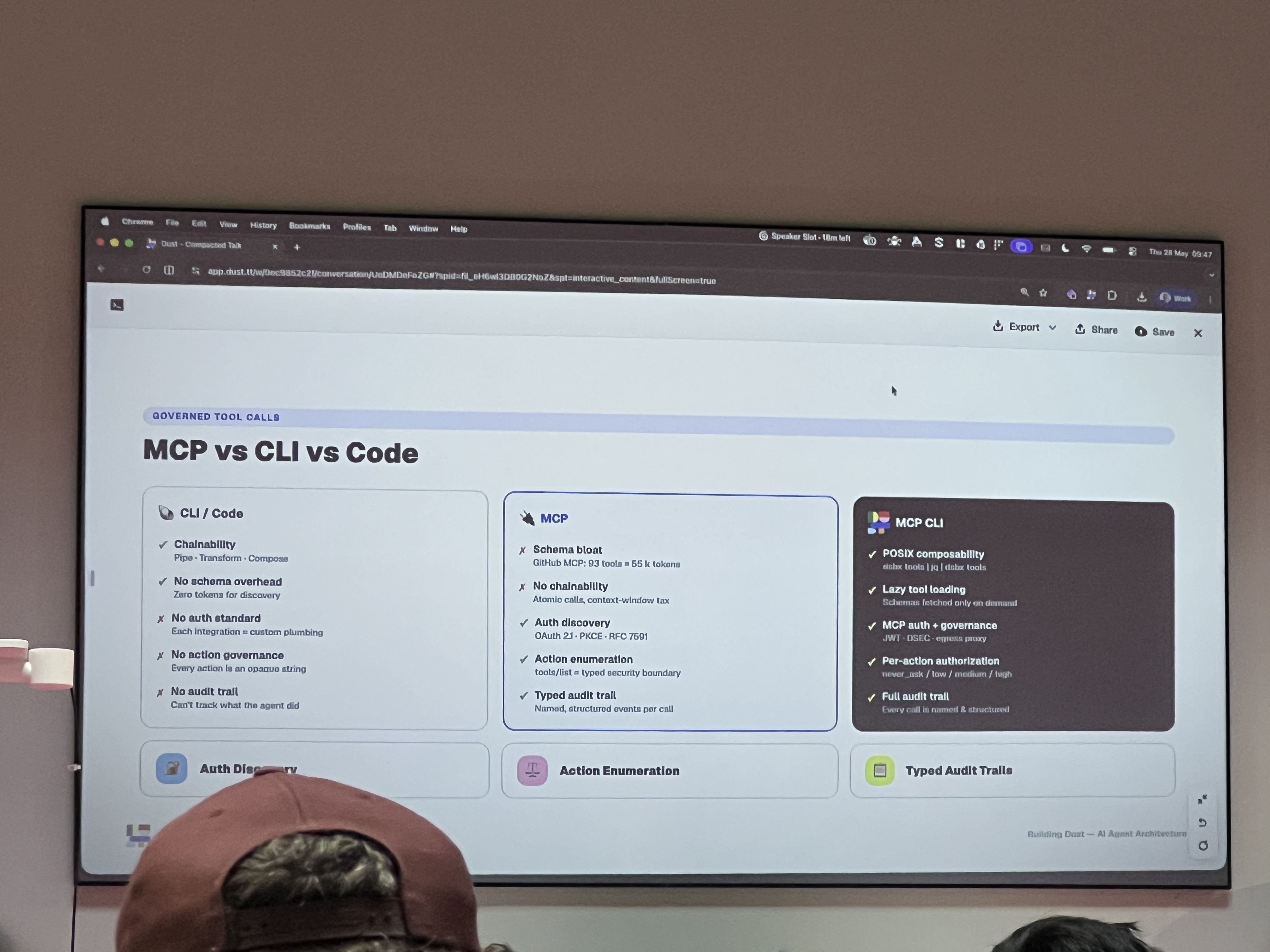
The short version:
- CLI/Code is chainable and has zero schema overhead, but every integration needs its own auth plumbing and there’s no audit trail — “can’t track what the agent did”
- MCP gives you auth discovery and typed audit trails, but you pay in schema bloat (they called out GitHub MCP: 93 tools = 55k tokens) and no chainability between calls
- MCP CLI is their proposed middle ground: POSIX composability, lazy schema loading (fetched only when needed), MCP-style auth and governance, per-action authorization levels
The per-action authorization bit is what caught my eye — never_ask / low / medium / high — a structured way to say “this action is safe to auto-approve, that one needs a human in the loop.” Most teams I know are handling this with a mix of vibes and prayer, so seeing a formal model for it was refreshing.
LobsterX: dissecting an agent with a scalpel
This talk took a different approach — instead of architecture philosophy, it was a live autopsy of a real agent (AI, not human).
Clelia Astra Bertelli — DevRel at LlamaIndex — built LobsterX — a document-processing agent that lives in Telegram. You send it a PDF and a task; it parses, extracts, classifies, reasons, and replies when it’s done. The whole agent is ~600 lines of code. The workflow orchestration underneath is ~1.5k. Three swappable LLM providers.

They used four anatomical metaphors: Brain (the LLM), Loop (the event-driven workflow), Eyes & Limbs (filesystem and tools), Ears & Mouth (how it talks to a human).

I found it to be a good framework to think about how to build an agent.
Structured outputs all the way down
The Brain section had something I’ll probably steal: every LLM call is constrained by a typed JSON schema. No free-form prose allowed, ever. One schema per operation type — a Think call looks different from an Act call — which forces a hard separation between reasoning and action at the code level.

There’s no “raw chat” escape window in the agent code. The wrapper exposes only structured-generation methods. This means the same schema works across OpenAI, Anthropic, and Google without any provider-specific branching in the agent logic.
I like this. The undeterministic nature of LLMs is a pain, but it’s a pain that can and should be managed with statically typed schemas.
The virtual filesystem
The Eyes section was about AgentFS — a virtualized filesystem layer built by Turso that LobsterX uses instead of the real machine FS. The agent gets read / write / edit / grep / glob. No delete. No shell execution. Credential files like .env are excluded entirely.
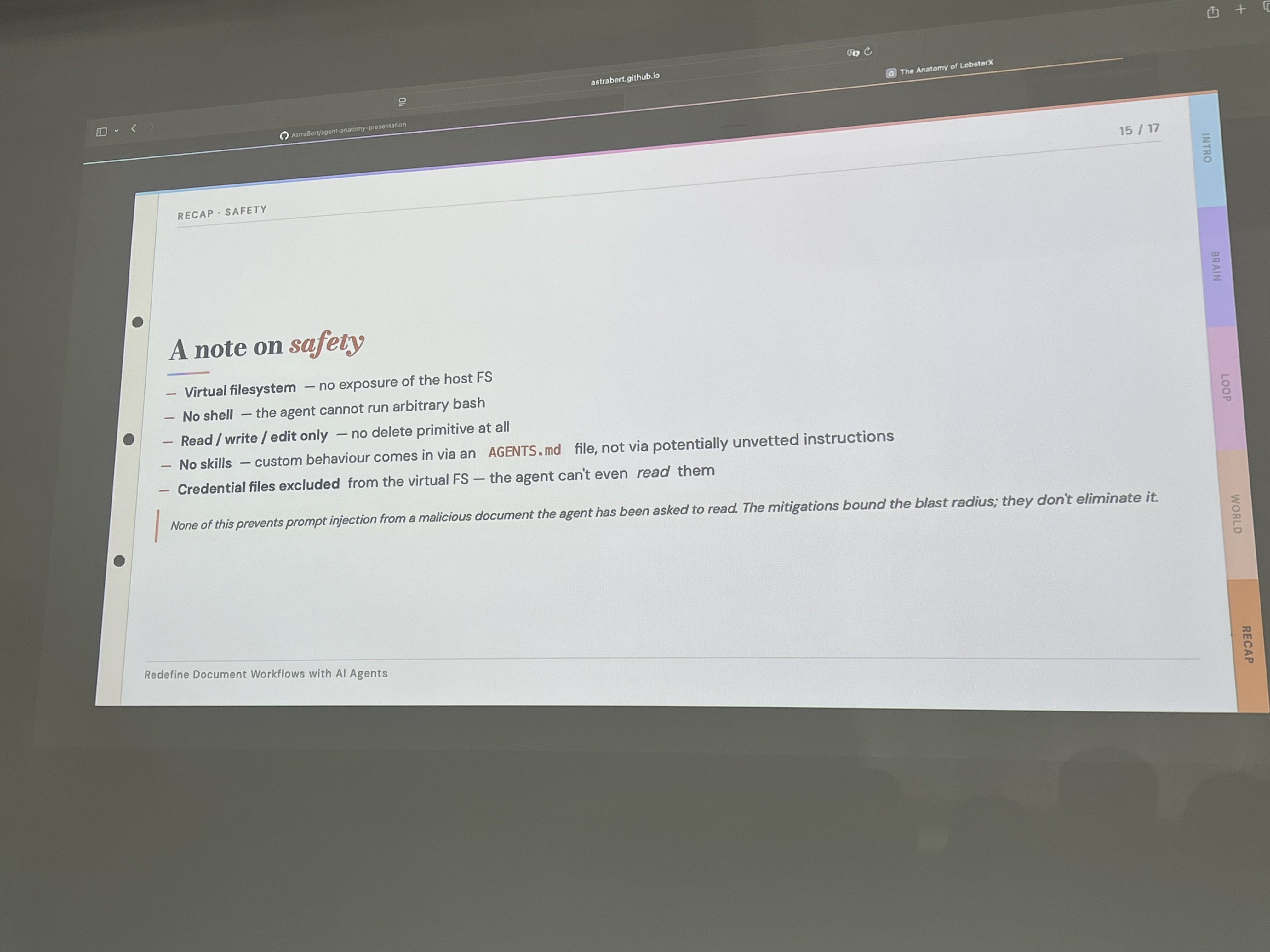
The slide had a line I wrote down verbatim: “If the agent is jailbroken into writing something destructive, the damage stays inside the virtual FS. Nothing leaks to the host unless you explicitly sync it.”
AgentFS from Turso is worth a closer look if you’re building agent infrastructure. It’s a standalone open-source project with Python, TypeScript, and Rust SDKs.
Ears & Mouth: async by default
The interface choice was deliberate. Telegram was picked because messaging is async — no spinner, no held-open HTTP connection. Documents come in as attachments, land in AgentFS, and the workflow starts. The agent pings you back when it’s done, which could be minutes or half an hour.
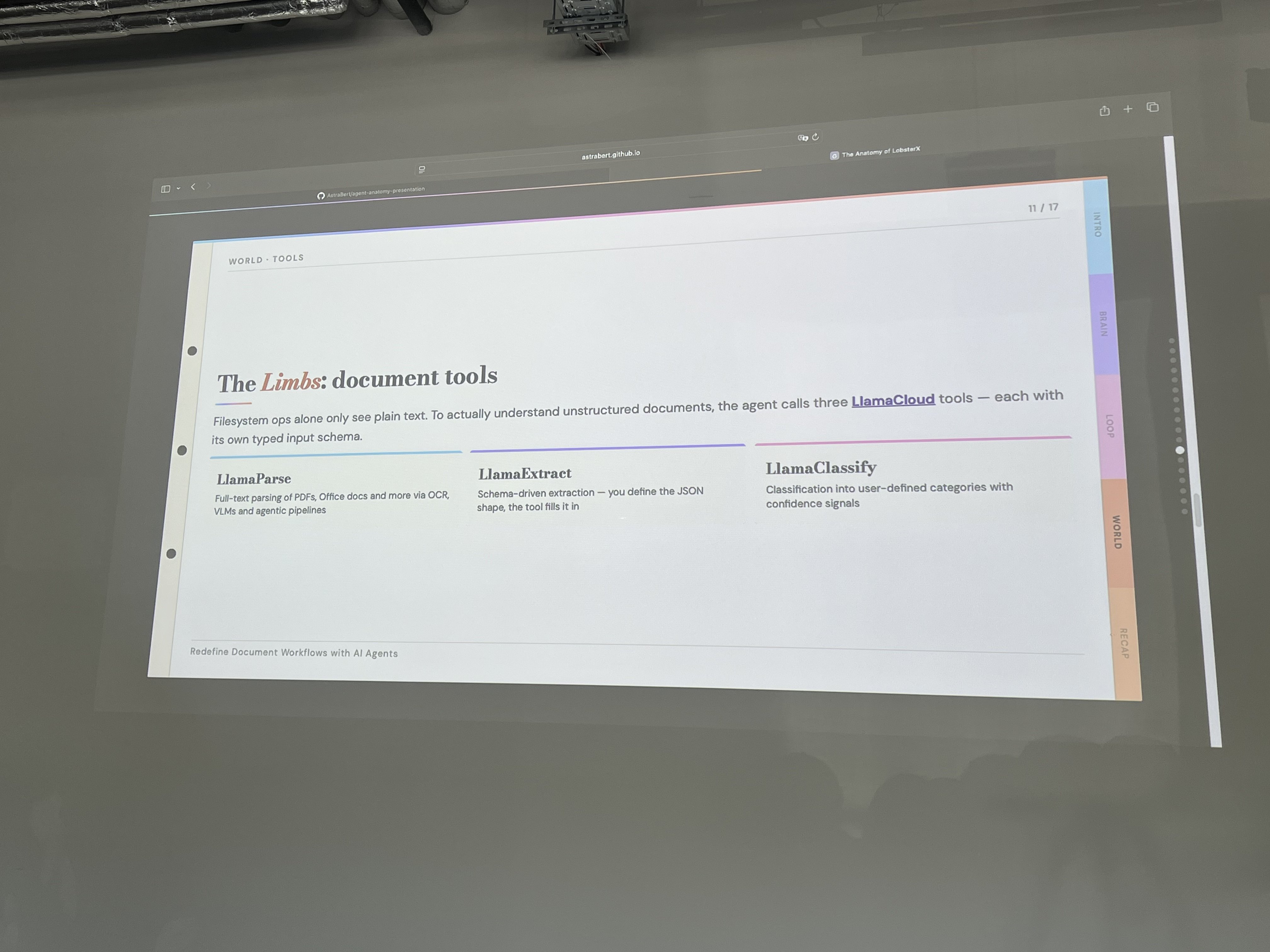
The slide had a line worth framing: “The right interface for a long-running agent isn’t a chatbot — it’s a colleague who replies when they’re finished.”
I’ve been building small personal agents that use the same pattern for my music project trianglecore.rocks — async Telegram bots that handle things I don’t want to babysit. There’s something genuinely calming about the UX once you stop expecting instant responses and start treating the agent like a person who’s doing a task.
A note on safety
The final recap slide was honest in a way I appreciated.
Virtual filesystem, no shell access, no delete primitive, credential files excluded, custom behavior via AGENTS.md not arbitrary instructions — all of that is real. And then the caveat: “None of this prevents prompt injection from a malicious document the agent has been asked to read. The mitigations bound the blast radius; they don’t eliminate it.”
This is the right way to talk about agent safety. The goal isn’t zero risk. The goal is knowing exactly what can go wrong and making sure the damage is contained when it does. Both talks today circled back to this: Dust with the egress proxy, LobsterX with the virtual filesystem. The industry seems to be converging on blast-radius thinking over “we solved it” thinking. That feels like a good direction.
Kafka as agent infrastructure
Steffen Hoellinger from Confluent made a case I wasn’t expecting: use Kafka and Flink SQL as the communication backbone for agents, rather than synchronous A2A protocols.

The argument is straightforward once you hear it. Synchronous agent-to-agent communication means one agent calls another and waits. For anything with real latency — document processing, external API calls, multi-step reasoning — that wait is a problem. You’re holding a connection open, you’re blocking, and if something fails midway, you’re rebuilding state from scratch.
Kafka flips this. Agents publish to topics and move on. Other agents consume when they’re ready. The workflow state lives in the stream, not in the call stack.
The Flink SQL angle specifically was about access: SQL via a gateway is readable by business users, AI included. Where the DataStream API requires “battle-tested Java code maintained by capable engineers,” Flink SQL can be generated, inspected, and modified by an agent without Java expertise. The slide framed this as a spectrum — DataStream for mission-critical, high-SLA workloads with a handful of complex jobs; Flink SQL for long-tail use cases, potentially millions of jobs, where AI is in the loop generating or modifying queries.
It’s a natural pairing with what LobsterX was doing with Telegram. The interface is async, the transport is async, and now the agent-to-agent communication is async too. The whole stack is designed around the assumption that work takes time.
Parloa: the engineer as product-minded architect
One line from the Parloa talk that I’m still turning over: “the engineer is now a product-minded architect.”
Parloa builds an AI agent management platform for enterprise contact centers — Allianz, Booking.com, SAP are customers, $3B valuation as of January this year. So when they say this, they’re not talking about hobby projects.
The framing resonates though. When you’re building agent-driven systems, the line between “does it work technically” and “does it do the right thing for the user” collapses. You can’t hand off the product decisions to a PM and go back to your terminal. The agent’s behavior, its tone, when it escalates, when it doesn’t — those are engineering decisions with product consequences. An engineer who doesn’t think in those terms is going to build something that passes tests and fails in production in ways no test would catch.
It’s a role shift I feel working on observability at deepset. Instrumenting a system well isn’t just a technical question. It’s: what does the person on call actually need to know? What does “this is working” mean to someone who uses the product, not someone who reads the metrics? The tooling we build shapes what people pay attention to.
Gradium: full-duplex voice AI
Not my domain, but a talk worth noting: Neil Zeghidour at Gradium making the case that current voice AI is fundamentally half-duplex.

The analogy is a good one. A walkie-talkie is half-duplex — one side talks, the other listens, you swap. A phone call is full-duplex — both sides can make noise at the same time. Human conversation works the same way: the listening party constantly produces small signals (“oh”, “hmm”, “right”) that aren’t interruptions, they’re acknowledgements that keep the other person talking. Today’s voice AI treats all of that as interruption and trips over it.
Gradium was founded by Neil Zeghidour, formerly of Google DeepMind and Kyutai — the research lab that released Moshi, the open-source full-duplex conversational AI they’ve commercialized.
The product they announced is Phonon — a ~100M parameter TTS model, private beta currently. Runs offline at 6x real-time on a single CPU core, which means it can live on a phone without ever touching a server. At that size, interesting for privacy-sensitive or truly offline use cases.
Langdock: prompt caching as the main cost lever
Balázs Csomor from Langdock went deep on LLM cost management — and caching was the whole answer.

The setup was a good rhetorical device: here’s everything you could do to cut LLM costs when that’s your core business — raise prices, add usage limits, remove expensive models, limit tool calling, prompt compression, smarter context windows. All struck through. The answer left standing: optimize prompt caching.
The second half was about making this observable. The dashboard they showed tracked Model Cache Rate across all models in production — gpt-5.2, claude-opus-4-6, gpt-5.4, claude-sonnet-4-6 — with average hit rates in the 70–80% range. The token composition view breaking down cached vs non-cached tokens per request, with a note that green (cached) should consistently grow to cover the full bar as a conversation progresses, was a clean way to think about it.
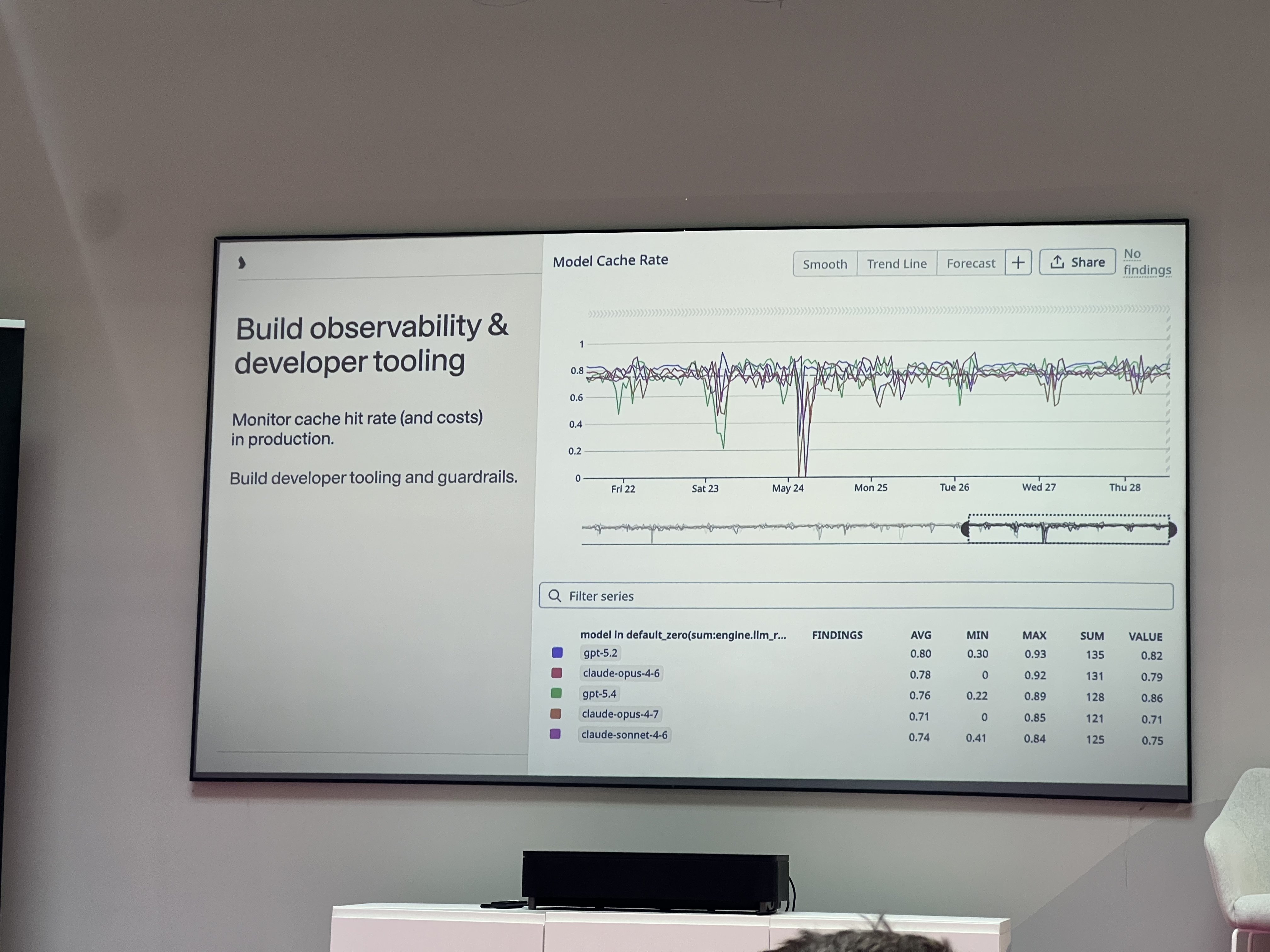
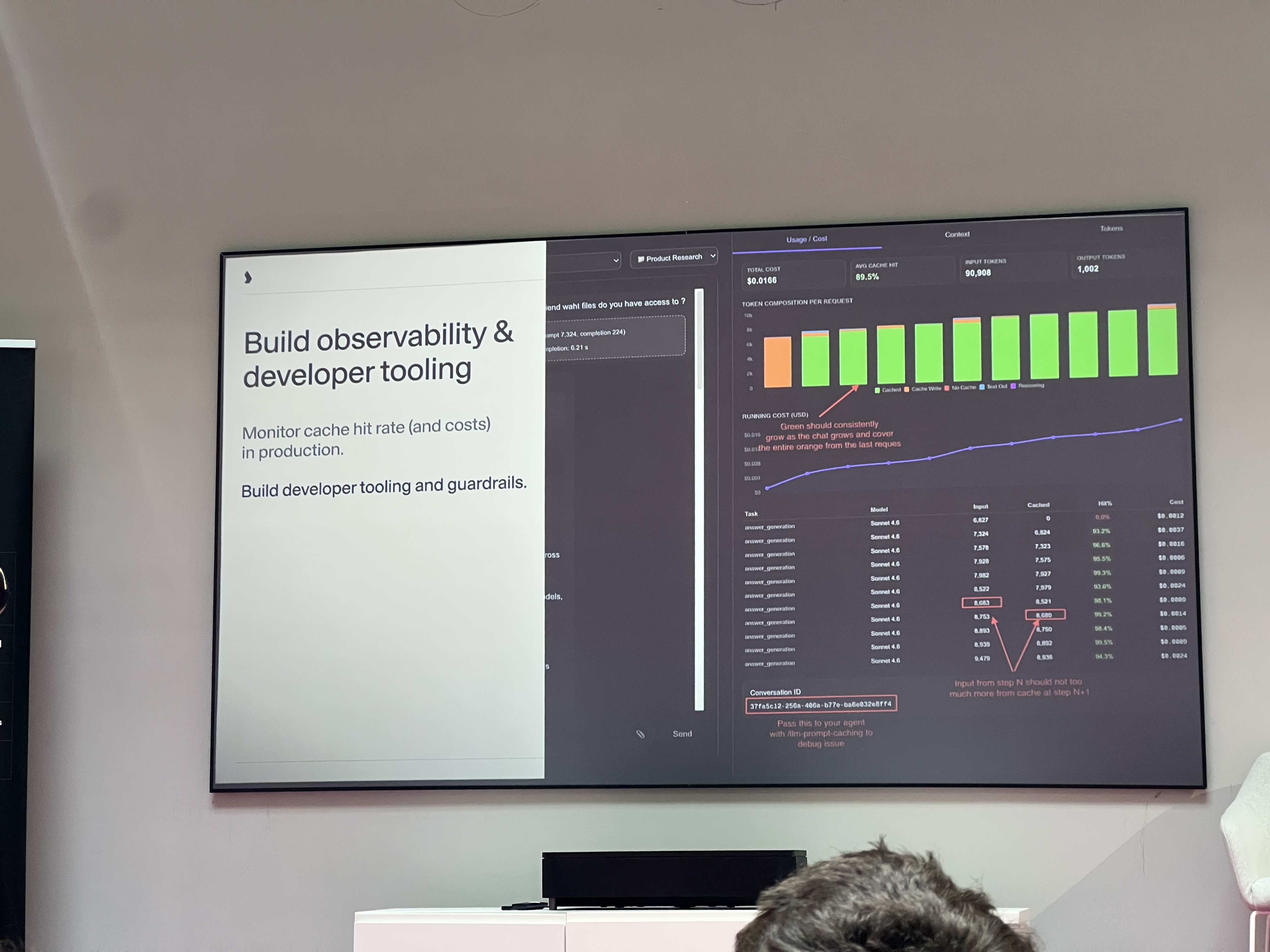
This resonates with the observability work I’m doing at deepset. Cache hit rate is exactly the kind of metric that doesn’t feel important until you’ve been paying for tokens you didn’t need to pay for for three months. It belongs on the same dashboard as latency and error rate.
Worth noting: Langfuse — whose observability UI appeared in the slides — has an official Haystack integration. If you’re building on Haystack and want this kind of cache visibility, it’s already there.
Google DeepMind: the cost optimization ladder
Lucia Loher and Patrick Löber from Google DeepMind picked up where Langdock left off on caching — but framed inside a more uncomfortable premise: inference cost grows faster than quality and value. Models improve, but the bill grows faster than the improvements justify. Their answer is three tools, stacked.
The first is prompt caching, and they went deeper than the basics. Explicit caching is manual — mark specific segments, control TTL, best suited for multi-turn agents where a large stable system prompt plus tool context repeats across turns. Implicit caching is automatic prefix reuse with zero code changes. The new concept worth knowing: block-wise caching — caching arbitrary segments independently, not just the leading prefix. For RAG pipelines this changes the math: cache different parts of your conversation separately and compose which blocks to include at query time. Less wasted computation when retrieval draws different subsets from the same sources each run.
The second lever: the Batch API. Not every inference needs to happen right now. Queue requests for off-peak processing, pay 50% less, get results within 24 hours. The tradeoff is latency — but there’s a large class of workloads that simply don’t need synchronous responses. Evaluation runs, document indexing, nightly analytics, anything feeding a pipeline rather than a user. For those jobs, paying for synchronous inference is paying a premium for speed you don’t need. (I made a note to myself: ask the team whether deepset exposes Batch API access to customers for models that support it.)
The third lever: Flex Inference — best-effort scheduling for non-critical work. Unlike Batch, it’s synchronous: you get a response immediately. But the compute is allocated opportunistically, so no throughput SLA. About 50% discount. Useful for scheduled background jobs, monitoring runs, anything running on a cron schedule where a slower response time is fine.
The recommended combination for maximum savings: explicit caching + Flex Inference. Stable context so the cache hits reliably; opportunistic scheduling so you’re not paying for reserved compute. For the right workloads, that’s not incremental — it’s structural.
Peec AI: the heavy model teaches, the cheap model ships
Peec AI is a Berlin company tracking brand visibility across AI search engines — ChatGPT, Claude, Gemini. Oğuz Gültepe, their Senior AI Engineer, gave a talk about how they built the AI inside their product.
This one had one of the best single slides of the day.

“A heavy model can judge what a cheap model produces.”
The idea is elegant: expensive models are slow and costly to run in production, but they’re genuinely smarter at evaluating quality. Cheap models are fast and cheap to run, but they need guidance. So don’t use the expensive model in production — use it to teach the cheap model, then throw it away.
The mechanism is a tight feedback loop:

Distill principles, not examples
The other key design decision: they instruct the optimizer to extract principles, not memorize good outputs.

After four turns, a generic instruction like “write an engaging opener based on the profile” grows into: reference one concrete detail from the profile, match the writing style of the bio, end with a question answerable in one sentence. The heavy model is reverse-engineering what makes a good output good, then encoding that as instruction.
That distinction matters. If you memorize examples, you overfit. If you extract principles, you generalize.
Miro: collaboration in the AI era
Łukasz Sągol, Director of Engineering at Miro, gave a talk about keeping teams aligned when agents are doing more of the work. It was a mixed bag, but one slide landed hard:
“Cursor made typing 10x faster. Typing was never your bottleneck.”
It’s a useful reframe. Most conversations about AI productivity focus on the wrong unit. The bottleneck in software is almost never keystrokes — it’s decisions, alignment, context. Tools that make you type faster don’t move that needle much.
The practical takeaway slide had three things worth keeping:
- Map your context — spend 30 minutes listing every place your team’s AI context lives. Write a one-pager that points to all of it. (Sounds obvious. Almost no one has done it.)
- Make one judgement call “durable” — pick a recurring decision (model choice, rollback rule) and write a one-paragraph ADR: what you decided, why, what you ruled out.
- Make one delegation rule explicit — pick one agentic workflow, write a paragraph on what the agent does without asking, what needs sign-off, and what never gets delegated. Share it.
The ADR idea for AI decisions is the one I’ll probably use. Engineering teams write ADRs for architecture — there’s no reason not to do the same for “why are we using this model” or “under what conditions does the agent escalate.”
Fin: the company that changed everything, including its name
The closing keynote was from Des Traynor, co-founder and CSO of Fin — formerly known as Intercom, rebranded just two weeks before the conference. The most energetic talk of the day, the perfect closing keynote.
The opening slide was a wall of text, and intentionally so:

“We changed our strategy, our company mission, our culture, what we build, how we build, our product momentum, our pricing + packaging, our team, our roles, our titles, our product differentiators, how we sell, how we compensate, we changed our branding, we launched new competitive brands, and 2 weeks ago we changed the name of the company.”
That’s not a pivot. That’s a full rebuild. From a $400M ARR business. And they did it fast.
The framing for why: a diagram showing what “Chat as UI” actually does to your addressable market.

Before: your users need to both know what they want to do and how to do it. The overlap of those two groups is your real market. After chat: knowing what is enough. The AI handles the how. The addressable circle expands dramatically.
It’s a clean way to explain why every legacy software company is scrambling right now. If your product used to require skill to operate, that reason just disappeared.
What future products look like

Their list of what winning products will look like:
- Own complete domain areas — less point solutions, fewer tools
- Fully agentic — automate everything
- Let you interact however you want — CLI, API, text UI, GUI, Claude
- Self-improving — proactively identify areas for improvement
- Strategic systems — inputs are policies and postures, not cases and tasks
And the line that closed it: “The primary performance vector is the quality and depth of the AI itself.”
Not UX. Not features. Not integrations. The AI quality is the product.
Grow the new muscles
The tactical slide was very direct:

“Your previous processes are hopelessly out of date. Solve for AI Reliability first. Design Exploration is a lot cheaper now, use it. Grow the new muscles, fast.”
The “new muscles” list: empirical evaluation, scientific rigor, causality (why did this metric move?), prompting, ML architecture, task decomposition, post-training, pre-training, understanding speed/cost/accuracy/hallucination tradeoffs. They back this with a research hub at fin.ai/research — papers on RAG evaluation, the Agency-Control-Reliability tradeoff for agents, LLM reranking. Worth bookmarking.

The role shift message echoed what Parloa said earlier: the new designer is also the front-end engineer, the new engineer is also the product manager. You own your domain end to end. The separation of concerns that used to make sense in a slower-moving world doesn’t map onto how AI products get built.
Takeaways
Two themes ran through almost every talk today, cutting across companies, scales, and domains.
The first is economics. Everyone is concerned about the cost of AI at production scale, and the solutions are converging on the same ideas from different directions. Prompt caching keeps tokens out of repeat inference. Model routing sends cheaper models where cheaper models are good enough. Fine-tuned SLMs narrow the task scope so a smaller model can match frontier quality at a fraction of the run cost. The judge-generator pattern — expensive model teaches, cheap model ships — is probably the most elegant framing of the whole problem: the intelligence belongs in the evaluation loop, not the production hot path. You pay once to distill judgment into a prompt, then run the cheap thing indefinitely.
These aren’t separate techniques. They’re the same architectural principle from different angles: heavy models belong offline, in the design and validation phase. Light models belong online.
The second is identity. Multiple talks made some version of the same claim: the role boundaries between designer, engineer, and product manager are dissolving. The designer who ships, the engineer who understands the customer and owns outcomes — that’s the emerging unit of work. The separation of concerns that used to make sense in slower-moving product cycles doesn’t map cleanly onto how AI products get built and improved.
I don’t build user-facing products. I’m an SRE, and I sit well behind the feature layer. But I felt this one. The way I approach my current work — replacing Datadog with an open-source observability stack and wiring it into an AI-native workflow — the question is never just “does it work.” It’s “does the person on call understand what they’re looking at, and does the system point them toward what to do next.” That’s a product question.
On the conference itself: it was good. A bit too dense for a single day — the talks were substantive enough that a second day to let things breathe (and actually talk to people between sessions) would have helped. The main stage had acoustic issues that made it hard to follow the speaker if you do not sit close to the stage. Small complaints. The topics were genuinely at the frontier, and the room felt like people who were building things rather than watching the AI wave from the shore. That combination is rarer than it should be.
Until next year.
